
Beyond Single Turns: Evaluating Chat Agents in Multi-Turn Dialogues
Uncovering What Really Matters in Multi-turn Chat Agent Performance



The era of simple question-and-answer bots is over. Today’s Large Language Models (LLMs) power sophisticated conversational AI that can handle complex, multi-step interactions in various settings. But this advancement comes with a new challenge: how do we know if they’re actually any good? Simple accuracy scores don’t cut it anymore. How do we systematically go about evaluating the entire conversation?
What is multi-turn evaluation? (And why is it different?)
Multi-turn evaluation is the process of assessing the quality of an entire dialogue between a user and an LLM, not just a single, isolated response. It focuses on the cumulative success of the interaction.
Single-Turn Example: Evaluating a factual question
User: “What is the capital of Japan?”
LLM: “The capital of Japan is Tokyo.”
Evaluation: The answer is factually correct. Pass/Fail.
Multi-Turn Example: Evaluating a customer support chatbot
User: “My internet is down.”
LLM: “I’m sorry to hear that. Have you tried restarting your router?”
User: “Yes, I did that already.”
LLM: “Okay, thanks for confirming. Let’s check for outages in your area...”
Evaluation: Does the LLM remember previous turns? Does it guide the conversation logically? Does it help the user properly?
As shown above- relying on single-turn metrics for multi-turn evals is like judging a movie by a single frame. A chatbot can be correct on every individual turn but still provide a frustrating user experience, miss the overall goal and not be coherent across consecutive turns. We need to define different multi-turn evaluation metrics to measure the qualities that actually define a good conversation.
The core challenge - Context is spread everywhere
The primary difficulty is that context is temporal and distributed. The information needed to judge a response in turn 5 might have been provided by the user in turn 1. The evaluation metric must be able to incorporate these temporal nuances in its calculations. Context being spread everywhere is what makes evaluating conversations fundamentally harder than evaluating simple prompt-completion pairs.
The rise of LLM-as-judge evaluation
For years, evaluating open-ended AI conversations was stuck between a rock and a hard place. On one side, we had classical automated metrics like ROUGE and BLEU, which measure word overlap between a model’s output and a reference answer. While fast and cheap, they are fundamentally insufficient for multi-turn conversations. A chatbot can provide a perfectly helpful and coherent response that uses completely different wording than the “correct” answer, causing it to fail these tests. These metrics simply cannot grasp abstract qualities like creativity, factual consistency, or conversational flow.
On the other side was the gold standard: Human Evaluation. Humans can easily judge the nuanced aspects of a conversation, but this approach is incredibly slow, expensive to scale, and often suffers from inconsistency between different raters. This created a massive bottleneck, making rapid iteration on chat models nearly impossible.
The breakthrough came with a new paradigm: using a powerful LLM to act as an impartial “judge”.
The Foundational Idea (LLM-as-a-Judge)
The 2023 paper “Judging LLM-as-a-Judge with MT-Bench” was a landmark study. It proposed that a powerful LLM, like GPT-4, could be used to automate the evaluation of open-ended questions. They found that GPT-4’s judgments agreed with human evaluators over 80% of the time, making it a scalable and reliable alternative. This method also unlocked the ability to evaluate abstract and nuanced metrics like conversation flow, helpfulness, toxicity, etc.
The paper also introduces MT-Bench to test their method, a challenging benchmark consisting of 80 high-quality, multi-turn conversational questions. This became a standard for assessing the conversational and instruction-following abilities of chat models over a variety of user-defined metrics.
Frameworks like Deepeval use this paradigm of evaluation to build a suite of multi-turn evaluation metrics - as we will discuss in the next sections.
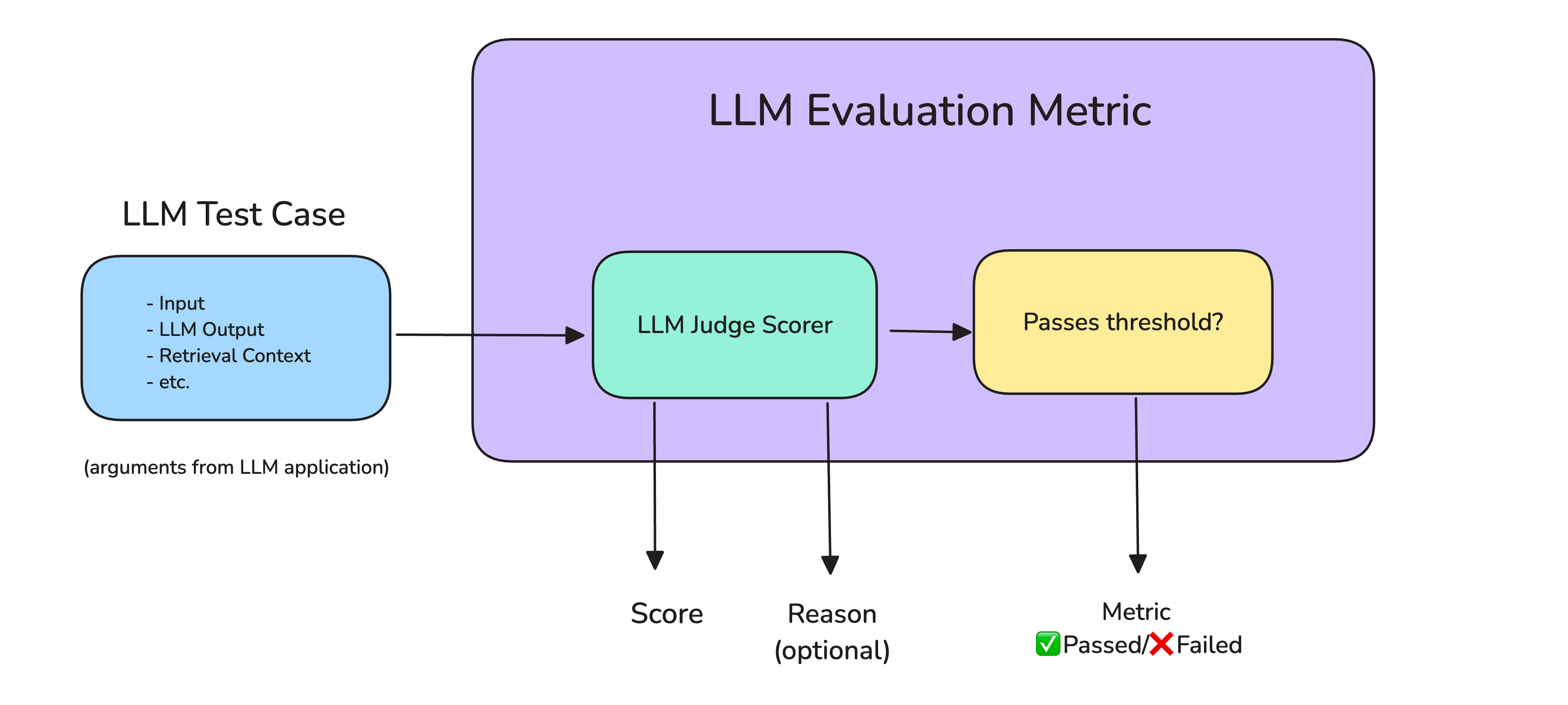
Adding Reliability (G-Eval)
The “G-EVAL” paper further refined this idea by moving beyond a simple scoring prompt to a more structured and transparent framework. Instead of asking the judge to produce a score directly, G-Eval introduces a three-step process that leverages Chain-of-Thought (CoT):
Evaluation Step Generation: First, G-Eval uses an LLM to take a broad, natural language criterion (e.g., “evaluate for coherence”) and automatically decompose it into a detailed, step-by-step evaluation checklist.
Judging: Next, the LLM judge uses this newly generated checklist to assess the text. Following each step, it provides a detailed CoT-based rationale before making a verdict on that specific point.
Scoring: Finally, the framework produces a score by combining the verdicts from the judging phase, weighting them by their log-probabilities to reflect the model’s confidence in its own assessment.
This structured approach, which forces the LLM to first create a rubric and then reason through it step-by-step, significantly improves the consistency and reliability of the final evaluation.
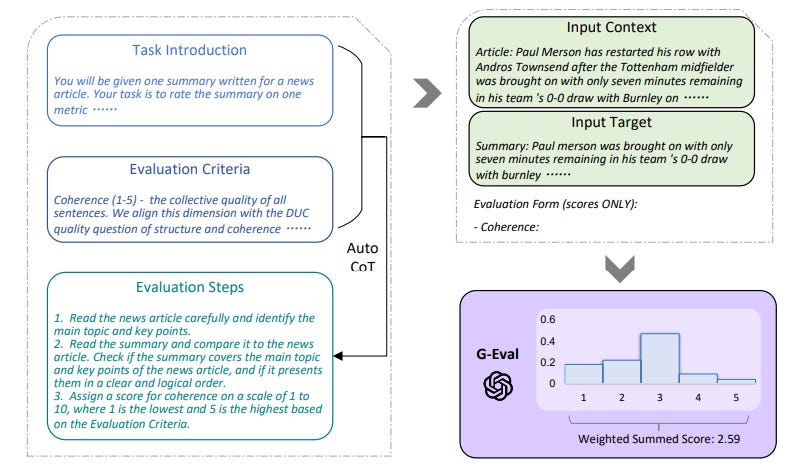
Extending on G-Eval, frameworks like Deepeval have also developed the concept of Conversational G-Eval, which adapts the structured, chain-of-thought approach of G-Eval specifically for the nuances of multi-turn dialogues.
Exploring Modern Metrics - DeepEval
DeepEval, drawing inspiration from the literature and focusing on what truly matters in multi-turn conversations, has developed multiple metrics to evaluate LLM conversations. Let’s take a deep dive into four such metrics, which use the LLM-as-a-Judge pattern to go beyond simple accuracy.
Turn Relevancy: Is the Conversation Making Sense?
What it is
Turn Relevancy acts as a coherence detector. It measures whether each assistant response aₖ, is logically relevant to the entire preceding context of the conversation.
How it works
This metric uses a sliding window approach. Given a conversation
C = [[u₁, a₁], [u₂, a₂], ..., [uₙ, aₙ]] and a window size k, the metric breaks the dialogue into overlapping segments. Eg (window size = 2):
window 1 - [[u₁, a₁], [u₂, a₂]]
window 2 - [[u₂, a₂], [u₃, a₃]] and so on
For each window, a judge LLM is asked if the final assistant response is relevant to the preceding context within that window.
The final score is the proportion of “yes” verdicts:
\( \text{Turn Relevancy} = \frac{\# \text{ "yes" verdicts}}{\# \text{ windows}}\)
Considerations
Cost-Context Trade-Off: The
window sizeis a critical parameter that must be tuned. A larger window provides deeper contextual evaluation but significantly increases the token cost and computational complexity (O(n)) of the metric.Cost Management: To manage costs in large-scale testing, the sliding window could be modified to include a “stride”. This would sample the conversation rather than evaluating every turn, trading granularity for better efficiency.
Role Adherence: Is the Chatbot Staying in Character?
What it is
This metric measures the assistant’s ability to consistently conform to a predefined persona or role, such as “a helpful and friendly pirate” or “a formal bank teller.” It is essential for maintaining brand identity and user trust.
How it works
Unlike the sliding window approach, Role Adherence processes the entire conversation in a single pass. The full dialogue and a description of the required persona (
chatbot_role) are passed to a judge LLM. The judge is prompted to review the entire conversation and return a list of all assistant turns that are inconsistent with the specified role.The score is calculated as the proportion of turns that were in character:
\(\text{Role Adherence} = \frac{\# \text{ total assistant turns} - \# \text{ out-of-character turns}}{\#\text{ total assistant turns}}\)
Considerations
Efficiency vs. Limitations: The single-pass design is highly efficient (O(1)) for a quick, holistic check. However, it’s vulnerable to the judge LLM’s context window limits for long dialogues and relies on a potentially fragile index-based reporting method.
Adapting for Scale: For very long conversations that might exceed context limits, the single-pass approach could be adapted into a chunking based approach, where the dialogue is broken into large, overlapping segments to balance a holistic view with technical constraints.
Knowledge Retention: Does the LLM Remember What I Said?
What it is
Knowledge Retention is a crucial metric that assesses the assistant’s ability to remember and correctly use facts provided by the user earlier in the conversation. This could be anything from the user’s name to critical information like dietary allergies.
How it works
This metric uses a meticulous two-phase process:
Knowledge Extraction: First, an LLM iterates through each user turn (u₁, u₂ … uₖ), to identify and extract key pieces of information into a structured format (e.g.,
{”Name”: “Deepak”}). This creates a running list of all facts the user has provided.Attrition Verification: Next, the metric iterates through each assistant turn (a₁, a₂, ... aₖ). For each turn, it provides a judge LLM with the assistant’s response and all facts extracted from previous user turns, asking: “Does this response forget or contradict any of these known facts?”
The score is the ratio of turns where the assistant correctly remembered everything:
Considerations
Cost Optimization: The two-phase design is exceptionally thorough but can be expensive (up to
2nAPI calls). This opens the door to cost-saving optimizations, such as using traditional NER for the extraction phase or processing facts in batches.Enhanced Nuance: The metric’s boolean verdicts could be evolved to a weighted scoring system. This would allow it to distinguish between critical memory failures (e.g., an allergy) and minor ones (e.g., a favourite color) for a more meaningful score.
Conversation Completeness: Did We Get Things Done?
What it is
This metric shifts focus from the quality of individual turns to the overall task success. It measures whether the assistant successfully addressed all of the user’s distinct goals or intentions by the end of the conversation.
How it works
This is another two-phase process that looks at the entire conversation from a high level:
Intention Extraction: An LLM first reads the entire conversation to identify and list all distinct goals the user expressed (e.g.,
[”Find a flight to London”, “Ask about vegetarian meal options”]).Satisfaction Verification: The metric then iterates through this list of intentions. For each one, it makes a separate LLM call, providing the full conversation and asking: “Was this specific intention fully satisfied by the end of the conversation?”
The final score is the ratio of satisfied intentions:
\(\text{Conversation Completeness} = \frac{\text{# "yes" verdicts (satisfied intentions)}}{\text{ # total intentions}}\)
Considerations
Cost Optimization: The two-phase design is exceptionally thorough but can be expensive (up to
2nAPI calls). This opens the door to cost-saving optimizations, such as using traditional NER for the extraction phase or processing facts in batches.Enhanced Nuance: The metric’s boolean verdicts could be evolved to a weighted scoring system. This would allow it to distinguish between critical memory failures (e.g., an allergy) and minor ones (e.g., a favourite color) for a more meaningful score.
But Who Creates These Metrics... and Which Ones Should I Use?
The rise of the LLM-as-a-Judge paradigm means the answer to the first question is increasingly: anyone can. The flexibility of the LLM-as-a-Judge paradigm is a double-edged sword for standardization. While powerful, it allows anyone to create bespoke metrics (e.g., “Empathy”), making it nearly impossible to compare results across different studies. This challenge is worsened by varied implementations; as we’ve seen, metrics may use a sliding window, a single pass, or turn-by-turn checks, all under a similar conceptual umbrella.
So, which metrics should you use? There is no universal set. The most effective strategy is to choose a suite of metrics tailored to your specific needs and use it consistently. The critical takeaway is that these scores are most valuable for tracking internal improvements and regressions, as they are not easily comparable to external benchmarks without understanding the underlying methodology.
Conclusion: From Lab Scores to Business Success
These “in-lab” metrics are powerful, but their ultimate value lies in their correlation with tangible business outcomes. Let’s look at how we can draw parallels between these metrics and business centric metrics for an e-commerce chatbot as outlined in this blog from Sobot.
By drawing on key performance indicators for e-commerce AI agents, we can see the direct connections:
Driving Sales: A high Conversation Completeness and Knowledge Retention score should directly lead to a higher Conversion Rate. When a bot successfully guides a user to the right product and remembers their preferences, a purchase is more likely.
Improving Efficiency: High scores across all metrics, particularly Turn Relevancy, contribute to a lower Average Resolution Time (ART). A coherent bot that doesn’t go on tangents solves problems faster.
Boosting Customer Loyalty: Excellent Role Adherence (maintaining a helpful brand voice) and Knowledge Retention (making the user feel heard) are critical for a high Customer Satisfaction (CSAT) score. A positive experience reduces the Abandonment Rate and encourages repeat business.
Reducing Costs: A bot that excels in Conversation Completeness achieves a higher First Contact Resolution (FCR) rate. When the bot solves the user’s issue on the first try, it prevents costly escalations to human agents.
The future of evaluation isn’t about finding one perfect metric. It’s about building a comprehensive dashboard that links these nuanced conversational scores directly to the business KPIs that matter most.
References
https://arxiv.org/pdf/2306.05685 - Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
https://www.confident-ai.com/blog/why-llm-as-a-judge-is-the-best-llm-evaluation-method - LLM as a judge (Confident AI)
https://arxiv.org/abs/2303.16634 - G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment
https://www.confident-ai.com/blog/g-eval-the-definitive-guide - G-Eval (Confident AI)
https://deepeval.com/docs/metrics-introduction - Multi-Turn eval metrics (DeepEval, Confident AI)
https://www.sobot.io/blog/evaluate-the-performance-of-chatbot-and-ai-agent-in-ecommerce/ - Evaluating an E-Commerce AI Agent (Sobot)
 | A guest post by
|
 | A guest post by
|