
RAG vs GraphRAG: A Performance Analysis and Implementation Guide
Comparing Architecture, Performance Metrics, and Real-World Applications



Retrieval-Augmented Generation (RAG) has been one of the biggest breakthroughs in the evolution of Large Language Models (LLMs). It gave LLMs the ability to fetch up-to-date, domain-specific information rather than relying only on their pre-trained memory. However, as data grows more complex and interconnected, traditional RAG begins to show its limits. That’s where GraphRAG steps in — a next-generation approach that introduces graph-based retrieval for deeper, context-rich understanding.
In this blog, we’ll explore how GraphRAG differs from standard RAG, comprehensive analysis between both across multiple dimensions, when each performs better, and when to use each approach.
Understanding the Fundamentals
What Is RAG?
RAG combines two key steps: Retrieval: Fetch the most relevant pieces of information (usually text chunks) from a vector database using semantic similarity search and Generation: Feed these retrieved documents into an LLM to generate a coherent, contextually grounded response. We have covered RAG in detail in this blog.
Example workflow:
Input: “Explain how solar panels work.”
Vector DB retrieves documents about solar cells, photons, and energy conversion.
The LLM summarizes and generates a final answer.
Advantages:
Easy to implement using embeddings (e.g., OpenAI, Cohere, or Hugging Face).
Works well for unstructured text (FAQs, documents, manuals, etc.).
Scales efficiently for most enterprise use cases.
Limitations:
RAG treats every document chunk as independent.
It struggles with relationships between entities (e.g., person–organization, cause–effect).
Retrieval is purely semantic, not relational — it might miss indirect connections important for reasoning.
What Is GraphRAG?
GraphRAG extends RAG by representing knowledge as a graph — where nodes represent entities or concepts, and edges represent relationships between them.
Example workflow:
Extract structured information (entities, relationships) from unstructured text.
Store this as a knowledge graph (using Neo4j, TigerGraph, or Memgraph).
During retrieval, use graph queries to fetch connected, context-rich information.
Feed the relevant subgraph into the LLM for generation.
Advantages:
Captures contextual relationships between facts.
Enables multi-hop reasoning — following chains of relationships to derive insights.
Reduces irrelevant retrieval by focusing on concept connections, not just keyword similarity.
Better for explainability — you can visualize why certain information was retrieved.
Note: We have used one of the popular datasets, NovelQA for our study and 4 widely used datasets for Query-based Summarization tasks, SQuALITY, QMSum, ODSum (ODSum-story and ODSum-meeting).
The Tale of Two Paradigms
Our systematic evaluation reveals a nuanced performance landscape where RAG excels at direct information retrieval (68.73% accuracy on single-hop queries), while GraphRAG demonstrates specialized strengths in complex reasoning scenarios. The data conclusively shows these approaches are complementary rather than competitive, with each method addressing distinct use cases and query patterns.
The NovelQA Dataset Findings: Performance Deep Dive
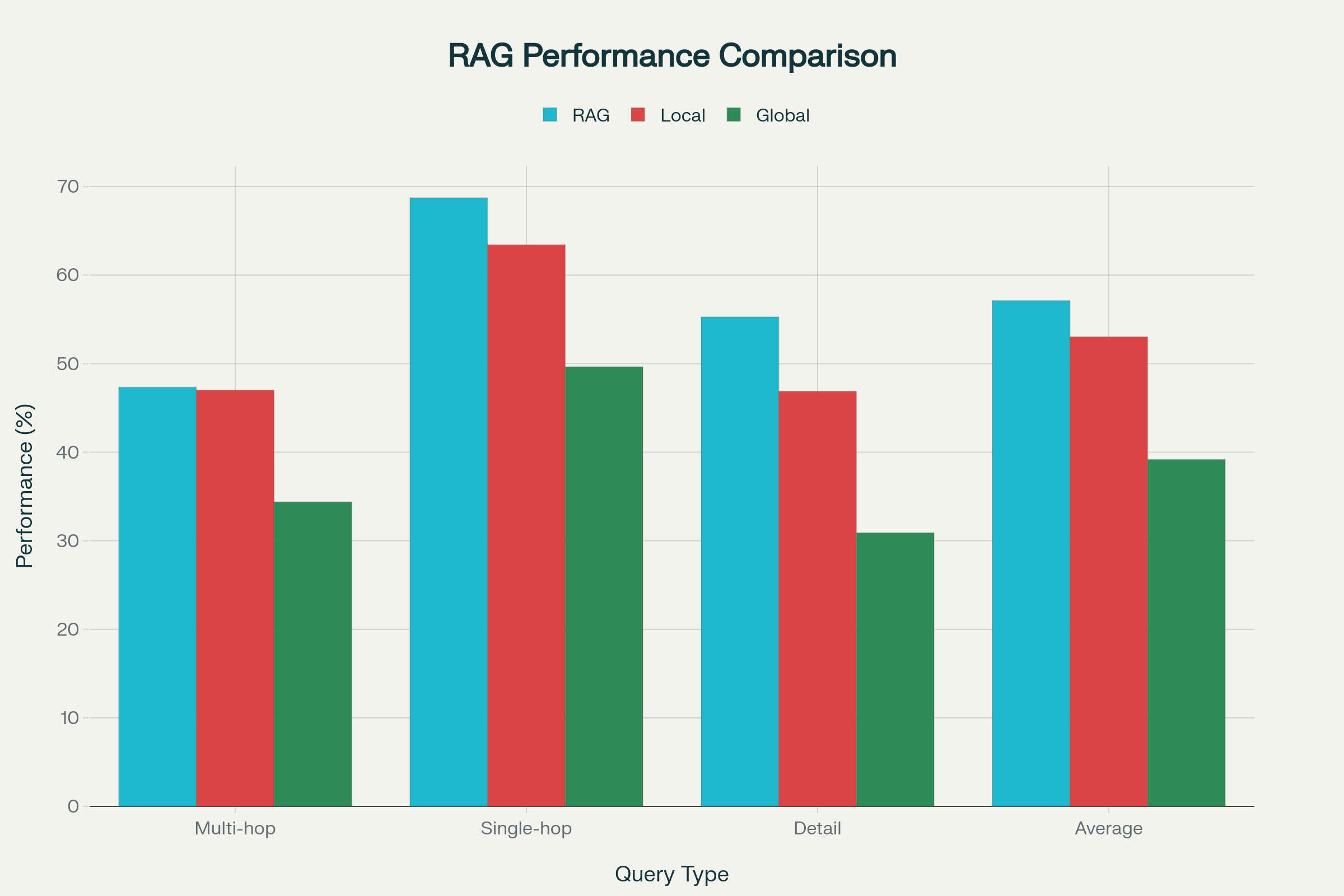
Performance Comparison: RAG vs GraphRAG on NovelQA Dataset (Llama 3.1-8B)
Summarization Task Performance Comparisions
Table: The performance of query-based single document summarization task using Llama3.1-8B
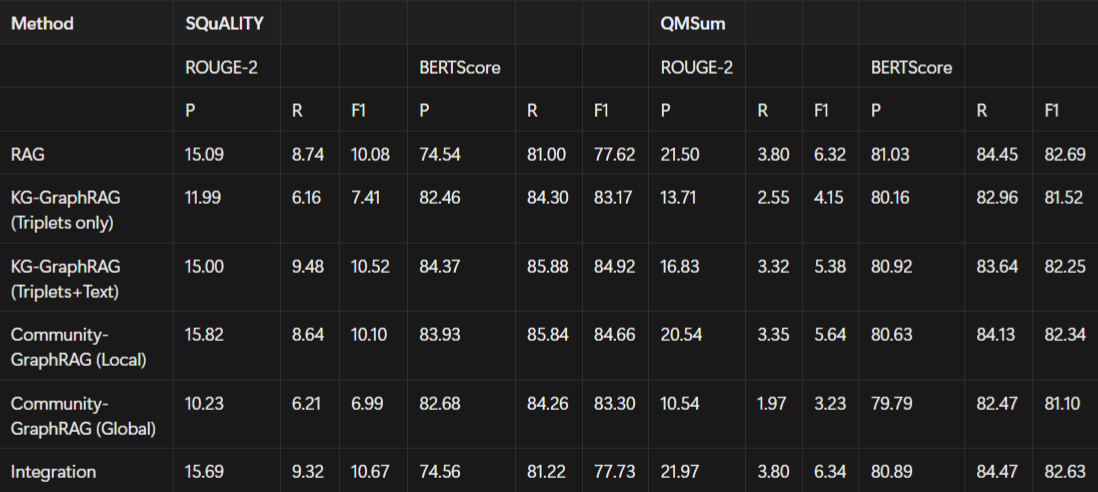
Table: The performance of query-based multiple document summarization task using Llama3.1-8B
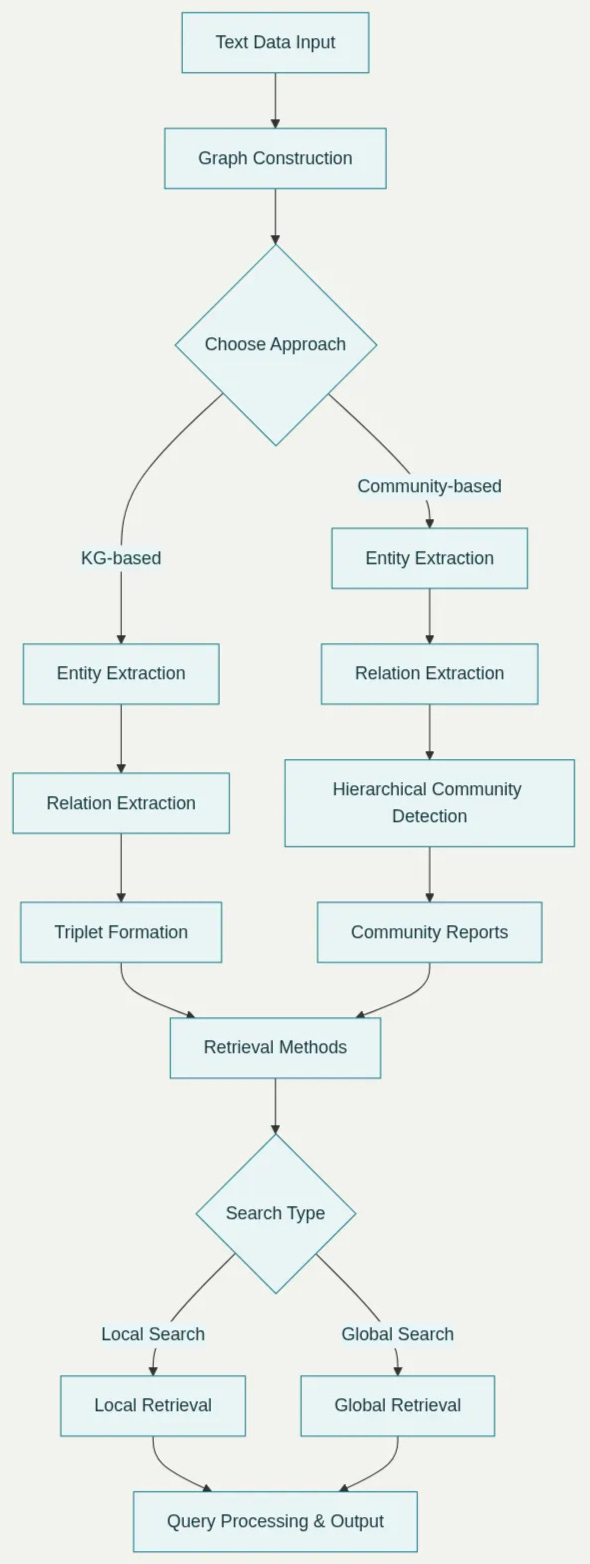
Implementation Architecture: From Text to Graph
Architecture Components:
Ingest & Chunking — break documents into logical chunks (paragraphs, sections). Add metadata (source, timestamp).
Entity & Relation Extraction — run LLMs / specialized NER/RE to extract entities and relations per chunk.
Triplet Store & KG Construction — convert extractions to (head, relation, tail) triplets and persist to a graph DB (Neo4j, JanusGraph, TigerGraph, RedisGraph).
Vectorization — embed chunks (and optionally entity descriptions / relation contexts) into vector DB (FAISS, Milvus, Pinecone).
Community Detection / Hierarchical Clustering — detect communities in the KG (Louvain, Leiden, hierarchical clustering) and produce multi-level summaries.
Global-Local Indexing — maintain: (A) a global index (vector) for semantic retrieval, (B) a local graph index for entity/relation retrieval and community-level summaries.
Retriever / Reranker — fuse results from vector retrieval + graph traversal; rerank by relevance, provenance, and connectivity score.
Prompting & Generator — craft prompts that include retrieved chunks, graph evidence (paths/triplets), and community summaries; call the LLM to generate the final answer with citations. This is done using Fact-Based vs Reasoning-Based Classification and LLM-as-a-Judge Evaluation.
Feedback Loop & Continuous Updating — store QA interactions, fine-tune rerankers, update KG and embeddings incrementally.
GraphRAG Construction
Knowledge Graph Construction:
Entity Extraction: LLM-based identification of entities from text chunks
Relation Extraction: Systematic relationship identification between entities
Triplet Formation: Structured representation as (head, relation, tail) triplets
Community Detection:
Hierarchical Clustering: Multi-level community structure creation
Community Summarization: Generated reports for each community level
Global-Local Indexing: Dual-layer retrieval mechanism
Implementation Complexity: High
Resource Requirements: Significant (graph storage, community detection, dual retrieval)
Latency: Higher (multi-step graph traversal and community lookup)
GraphRAG Construction Process: From Unstructured Text to Graph-based Retrieval System
Evaluation Methodology and Critical Analysis
We can implement a sophisticated query classification system to route queries optimally:
Fact-Based vs Reasoning-Based Classification:
Fact-Based: Direct retrieval from knowledge source, no multi-step reasoning required
Reasoning-Based: Cross-referencing multiple sources, logical inference, multi-step reasoning
LLM-as-a-Judge Evaluation Criteria:
Comprehensiveness: Full query coverage and relevant information inclusion
Global Diversity: Broad, internationally inclusive perspectives avoiding regional bias
Critical Finding: Position bias detected in LLM evaluations - changing the order of presented results significantly affects judgments, highlighting evaluation methodology limitations.
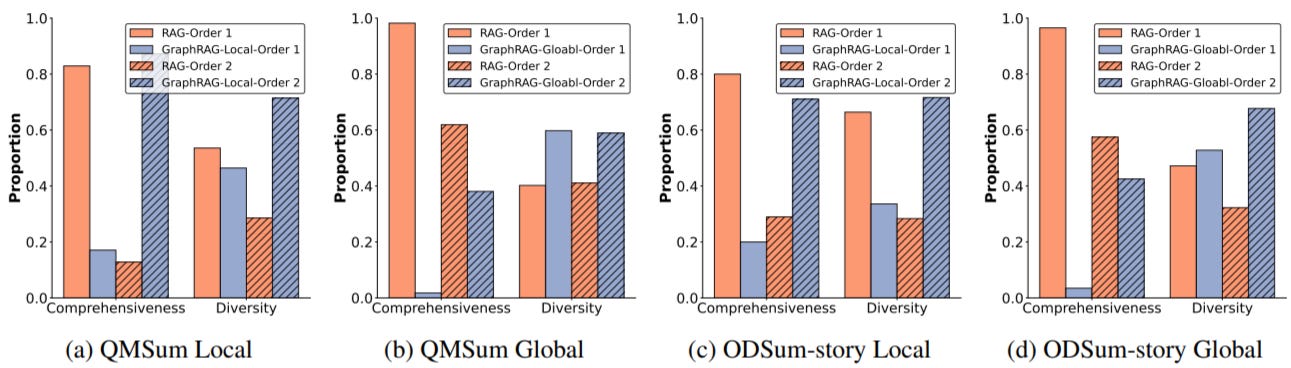
Figure: Comparison of LLM-as-a-Judge evaluations for RAG and GraphRAG. “Local” refers to the evaluation of RAG vs. GraphRAG-Local, while “Global” refers to RAG vs. GraphRAG-Global
Prompt for Query Classification
System Prompt: Classifying Queries into Fact-Based and Reasoning-Based Categories You are an AI model tasked with classifying queries into one of two categories based on their complexity and reasoning requirements. Category Definitions
Fact-Based Queries
The answer can be directly retrieved from a knowledge source or requires details.
The query does not require multi-step reasoning, inference, or cross-referencing multiple sources.
Reasoning-Based Queries
The answer cannot be found in a single lookup and requires cross-referencing multiple sources, logical inference, or multi-step reasoning. Examples Fact-Based Queries {{ Fact-Based Queries Examples }} Reasoning-Based Queries {{ Reasoning-Based Queries Examples }}
Prompt for LLM-as-a-Judge
You are an expert evaluator assessing the quality of responses in a query-based summarization task. Below is a query, followed by two LLM-generated summarization answers. Your task is to evaluate the best answer based on the given criteria. For each aspect, select the model that performs better. Query {{query}} Answers Section The Answer of Model 1: {{answer 1}} The Answer of Model 2: {{answer 2}} Evaluation Criteria Assess each LLM-generated answer independently based on the following two aspects:
Comprehensiveness
Does the answer fully address the query and include all relevant information?
A comprehensive answer should cover all key points, ensuring that no important details are missing.
It should present a well-rounded view, incorporating relevant context when necessary.
The level of detail should be sufficient to fully inform the reader without unnecessary omission or excessive brevity.
Global Diversity
Does the answer provide a broad and globally inclusive perspective?
A globally diverse response should avoid narrow or region-specific biases and instead consider multiple viewpoints.
The response should be accessible and relevant to a wide, international audience rather than assuming familiarity with specific local contexts.
Hybrid Implementation Strategies: Best of Both Worlds
Strategy 1: Intelligent Query Routing (Selection Approach)
Implementation Architecture:
def classify_and_route(query):
query_type = llm_classify(query) # fact-based vs reasoning-based
if query_type == “fact-based”:
return vanilla_rag(query)
else:
return graphrag_local(query) # Specialized reasoning capability
Performance Benefits:
Computational efficiency through single-method processing
1.1% improvement over best single method baseline
Strategic leverage of each system’s strengths
Strategy 2: Integration Approach (Simultaneous Processing)
Implementation Architecture:
pythondef integrated_retrieval(query):
rag_results = vanilla_rag(query)
graphrag_results = graphrag_local(query)
combined_context = merge_and_rank(rag_results, graphrag_results)
return generate_response(query, combined_context)
Performance Benefits:
6.4% improvement over best single method (MultiHop-RAG dataset with Llama 3.1-70B)
Superior performance across diverse query types
Comprehensive information coverage through dual retrieval
Trade-off Analysis:
1.5-2x computational cost for dual processing
Increased system complexity and maintenance overhead
Higher latency but significantly improved accuracy
Production Implementation Decision Framework
This framework helps decide whether to use RAG, GraphRAG, or a Hybrid system, based on your data, query types, and performance priorities.
When to Choose RAG
Use RAG if your system mostly answers straightforward, factual questions. It’s lightweight, fast, and ideal when you just need to retrieve relevant text and summarize it.
Choose RAG when:
Most queries are simple or single-hop (e.g., “What is X?”, “Who founded Y?”).
Speed is critical — you need answers in under ~500ms.
You have limited compute or budget.
Your knowledge base rarely changes (e.g., product manuals, company FAQs).
Expected Benefits:
Fast and efficient responses.
Low setup and maintenance cost.
Stable performance for simple retrieval tasks.
When to Choose GraphRAG
Use GraphRAG if your questions require connecting multiple pieces of related information. It builds a knowledge graph so the system can reason across entities and relationships.
Choose GraphRAG when:
Many queries involve reasoning or relationships (e.g., “How are A and B connected through C?”).
You need domain understanding (e.g., legal, biomedical, scientific research).
You can afford higher computational cost for better accuracy.
Quality and interpretability are more important than latency.
Expected Benefits:
Strong performance on multi-hop and analytical queries.
Clearer reasoning and traceable context (via graph connections).
Deeper understanding of entity relationships.
When to Implement Hybrid Strategies
Use a Hybrid system when your workload mixes both simple and complex queries. This combines the speed of RAG with the reasoning power of GraphRAG.
Choose Hybrid when:
Your queries vary in complexity — some are factual, others need reasoning.
You want maximum accuracy across all question types.
You have infrastructure that can support two retrieval systems.
You expect future growth in query complexity.
Expected Benefits:
~6% improvement in overall performance versus using either method alone.
Handles both simple lookups and relational reasoning.
Adaptable to evolving business needs.
References
https://arxiv.org/pdf/2502.11371 - RAG vs. GraphRAG: A Systematic Evaluation and Key Insights
https://arxiv.org/pdf/2502.06864 - Knowledge Graph-Guided Retrieval Augmented Generation
https://arxiv.org/pdf/2504.05163 - Evaluating Knowledge Graph Based Retrieval Augmented Generation Methods under Knowledge Incompleteness
https://arxiv.org/pdf/2404.16130 - From Local to Global: A GraphRAG Approach to Query-Focused Summarization
https://arxiv.org/pdf/2501.00309 - Retrieval-Augmented Generation with Graphs (GraphRAG)
https://www.sciencedirect.com/science/article/abs/pii/S1474034624007274 - Hybrid large language model approach for prompt and sensitive defect management: A comparative analysis of hybrid, non-hybrid, and GraphRAG approaches
https://www.sciencedirect.com/science/article/pii/S1877050924021860 - A Survey on RAG with LLMs
https://tailoredai.substack.com/p/complete-guide-to-rag-retrieval-augmented?r=5rz4n7 - Complete Guide to RAG (Retrieval Augmented Generation)
 | A guest post by
|
It would be interesting to know if you've tried a unified graph that has both the graph of the chunks (with vector embeddings) and metadata as nodes/properties, + the named entities graph
And how does retrieval look like there in terms of latency and accuracy?