
The Fine-Tuning Knowledge Injection Experiments: A Complete Story
A Practical Exploration of Fine-Tuning’s Strengths and Shortcomings



The Quest Begins
In the rapidly evolving landscape of artificial intelligence, we constantly seek ways to enhance large language models with domain-specific knowledge. This is the account of an experiment that tested fine-tuning’s ability to inject new knowledge into pre-trained models.
The Initial Hypothesis
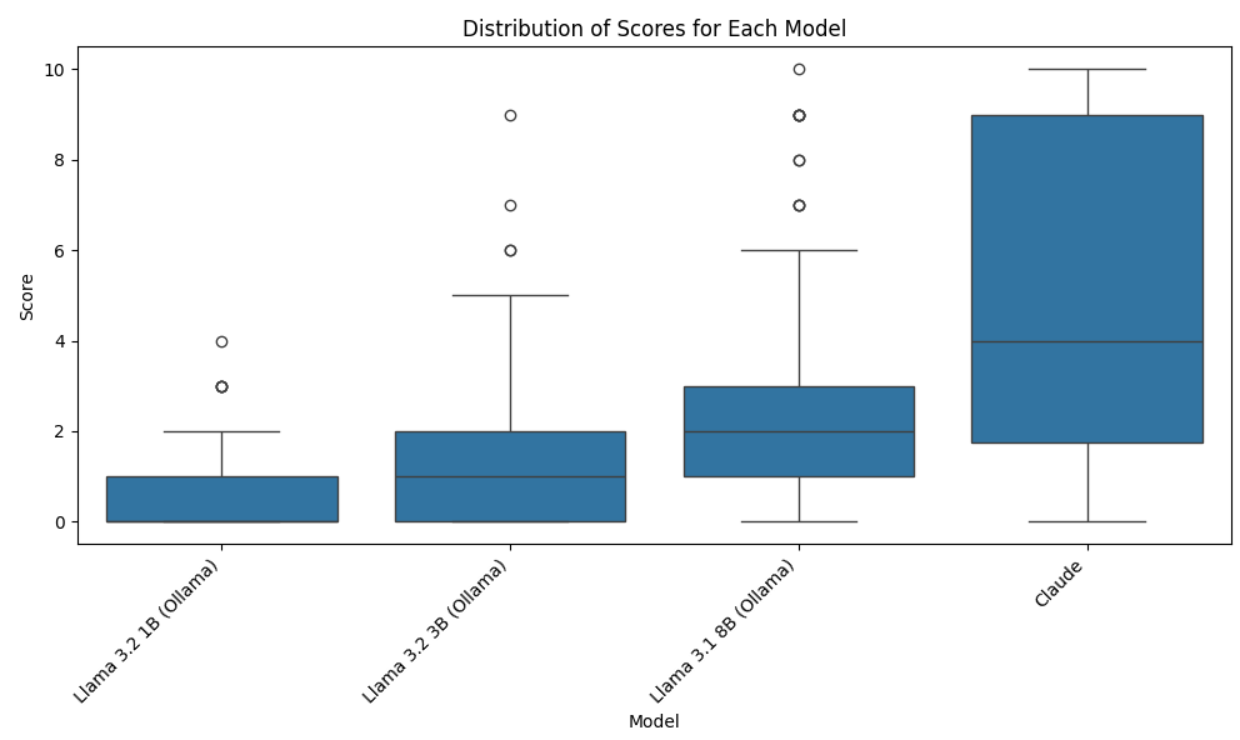
We began with an assessment of four base models on the ITR dataset using an LLM-as-a-judge framework. The results revealed a clear factual accuracy gap across models. Motivated by this, we set out to test whether fine-tuning could close the gap. Our mission was straightforward: take a powerful LLaMA 3.1 8B base model and fine-tune it using LoRA (Low-Rank Adaptation) to inject knowledge from a curated FAQ dataset sourced from the ITR website. The hypothesis was simple: if we fine-tuned properly, the model should learn new facts and information.
The First Experiment: Unexpected Revelations
Setup and Expectations
We configured the experiment with what we believed were reasonable parameters:
LoRA rank: 64
Alpha: equal to rank (64)
Learning rate: 1e-4
Dataset: ITR website FAQs, used as-is without modification
We set up a rigorous evaluation framework, employing another LLM as a judge to assess the factual accuracy of answers generated by our fine-tuned model compared to responses from Claude and the original base model.
The Surprising Discovery
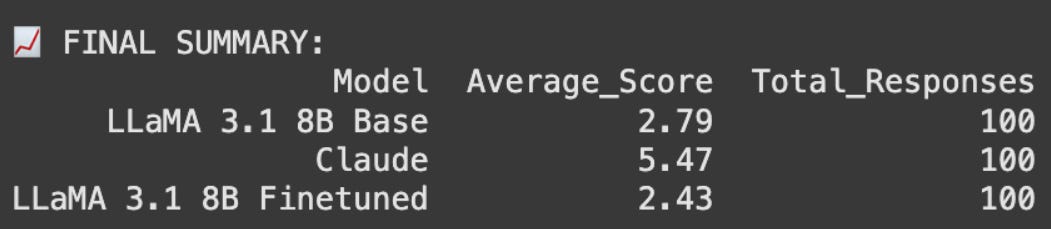
The fine-tuned model did not just fail to learn new information. It also performed worse than the base model on questions it had previously answered correctly. These were not obscure examples but training questions the model had just seen. This was not catastrophic forgetting in the usual sense, where performance drops on unrelated tasks. Instead, the model was losing knowledge on the very data it was trained on.
The Gradient Hypothesis
We hypothesized that strong gradients from inconsistent examples in the dataset pulled the model toward a local minimum that did not preserve existing knowledge. In effect, the fine-tuning process damaged knowledge the base model already had.
The Second Wave: Reformatting and Refinement
Addressing the Format Problem
Suspecting that formatting inconsistencies contributed to the issue, we reformatted all ground truth answers with Claude to ensure uniform style and structure across the dataset.
Persistent Challenges
The fine-tuned model did show one improvement: it consistently matched the style of the reformatted answers. However, factual accuracy still did not improve. We also tried much higher LoRA ranks and alpha values. While training loss decreased, performance on factual accuracy stayed flat. The model was clearly learning how to phrase answers rather than acquiring new information.
The Reality Check: Scientific Validation
Discovering Corroborating Evidence
While grappling with these results, we found research that aligned with our findings. One paper concluded: “Fine-tuning fails to inject knowledge into LLMs (in contrast to a limited success of pretraining), and LoRA does not seem to be the root cause of this failure.”
Beyond LoRA: Full-Weight Fine-Tuning
The same research also tested full-weight fine-tuning to see if the limitation was specific to LoRA. The results were clear. Even with full parameter updates, knowledge-level improvements were not observed. The limitation appeared to be fundamental to fine-tuning itself.
The Broader Implications
Literature Review Consensus
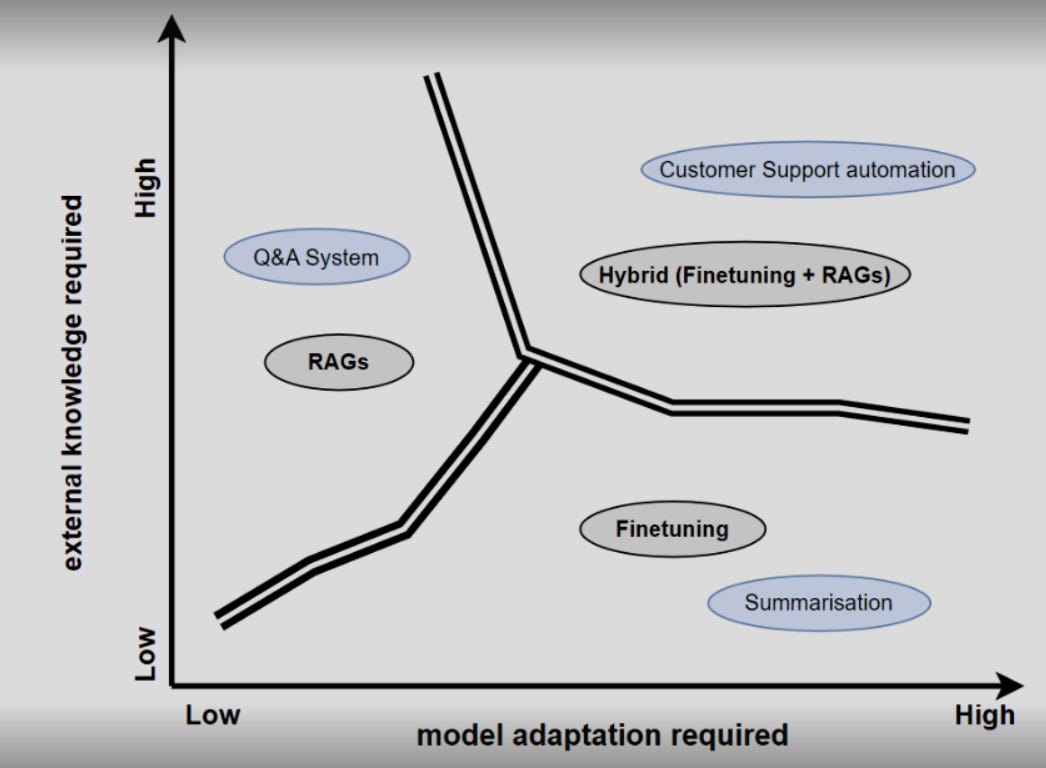
As we reviewed more studies, a pattern emerged. The consensus across research pointed to the same conclusion: for knowledge injection tasks, Retrieval-Augmented Generation (RAG) is more reliable than fine-tuning. RAG consistently outperforms fine-tuning when the goal is to add factual knowledge.
Lessons Learned
The Nature of Fine-Tuning
Our experiments showed that fine-tuning is best at adapting models to specific styles, formats, and behavioural patterns. It can teach a model how to respond but not reliably what to know. The fine-tuned models successfully learned the formatting and style of target answers but did not acquire the underlying facts.
The Knowledge Injection Challenge
This highlights a key distinction between knowledge acquisition and knowledge application. Fine-tuning can adjust how information is expressed, but adding entirely new factual knowledge appears to require different approaches.
The Value of Empirical Research
Most importantly, these experiments reinforced the importance of testing assumptions with rigorous experimentation. We systematically tested our initial hypothesis, and when the results did not align with expectations, we reported them transparently. This process provided valuable clarity about the actual capabilities of fine-tuning.
Summary
This work, while not achieving the intended breakthrough in knowledge injection, provided useful insights into the limitations and appropriate applications of fine-tuning technology. We learned what does not work and added to the body of evidence that helps the AI community decide when and how to use fine-tuning.
Our findings suggest that in AI research, progress often comes not from confirming assumptions, but from testing them and sharing results openly. The search for effective knowledge injection methods continues, now with a clearer understanding of the boundaries of fine-tuning and where alternative approaches like RAG may be more productive.
 | A guest post by
|
 |
|